

Despite recent advances, the difficult reality is that data science remains a labor-intensive field. Data analytics projects can take months or even years to come to fruition, depending on the complexity and accessibility of the data environment.
The global shortage of data science talent is further exacerbating things. Pre-pandemic, a Gartner study found that despite plans to increase AI projects by 5x over three years, one of the top challenges to adopting AI was the lack of data science skills. And this issue seems only to be intensifying over time. According to a PwC study, in 2012, over 50% of CEOs worried their employees lacked essential skills, threatening the company's growth potential. In 2019, that worry increased to 79% and primarily centered around a lack of tech-savvy leaders and employees.
Data science skills retention is becoming increasingly difficult with record low tech unemployment and the Great Resignation in full swing. With 65% of data scientists unhappy in their current roles and over half looking for a way out, companies are entering panic mode. The pandemic essentially widened the skills gap, made the job market more competitive, and increased turnover. As a result, companies worldwide are struggling to execute successful AI initiatives with insufficient talent.
The War for Data Science Talent
Today, the data talent crunch is a significant inhibitor to many organizations' growth strategies. In fact, the New York Times estimates there are only 10,000 people in the world with the education, experience, and talent necessary to develop the AI technologies that businesses are betting on for their success. This makes recruiters' jobs nearly impossible, forcing them to search for an elusive technical skillset. In addition, the increased demand for technical talent has resulted in 20-40% wage inflation, making it even more challenging to compete against deep-pocketed tech giants for a limited pool of candidates.
It’s not only the lack of supply creating a war over talent; it’s also a lack of AI success. On average, 85% of AI and machine learning projects fail to deliver value, and only 53% of projects make it from prototype to production.
So how do you improve the success of AI projects without hiring more data scientists? Companies have a choice to make: attempt to compete in a ridiculously competitive labor market or try to simplify the job of the data scientists you already have.
The Data Scientist’s Neverending To-Do List
The art and science of building and training models may be the most valuable steps in the data science workflow; however, they're not the most time-consuming. Data scientists actually spend the majority of their time on data preparation and pre-processing instead of analysis. As a result, data scientists have to expend time and resources centralizing data into one location before they can start analyzing it.
This process often starts with getting approvals for access to relevant datasets. Depending on the number of stakeholders and datasets, these approvals can take weeks or even months. In addition, gaining access becomes even more complicated if the datasets contain personal identifiable information (PII), personal health information (PHI), or if they exist across multiple regulatory jurisdictions. Legal teams will likely be involved in that case, resulting in compounding delays and hefty legal bills. Not to mention the time associated with masking and anonymizing sensitive datasets—potentially eroding valuable signals in the process.
Once data scientists have cleared the compliance and privacy hygiene hurdles, they still have to duplicate, centralize, and clean the data before the real "data science" begins. In total, data preparation can account for nearly 80% of a data scientist's job, meaning they only have the remaining 20% to spend on data analysis.
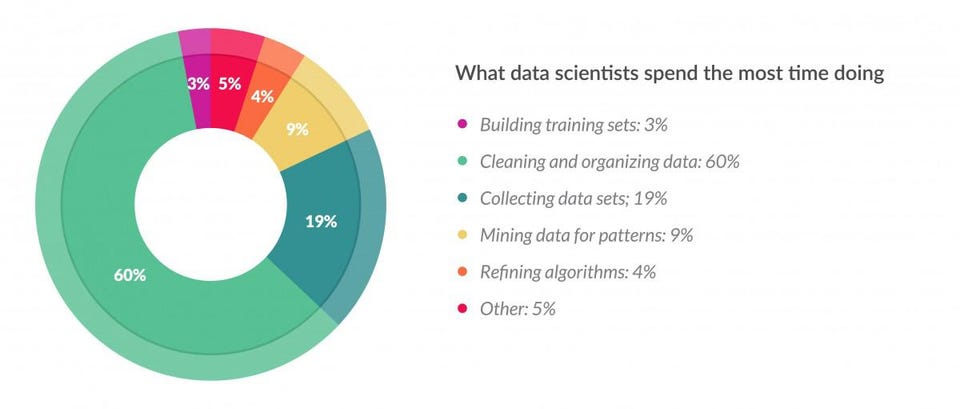
The role of the data engineer was created to take on this burden. However, the reality is that data scientists continue to be entangled or directly responsible for a lot of this data work. Ultimately, this contributes to emerging retention issues, with 76% of data scientists saying cleaning and organizing data is the least enjoyable part of their job. The problem will only get worse as the number of AI projects increases. Data scientists will continue allocating more time toward administrative tasks than data analysis unless something changes.
Allowing Data Scientists to Focus on Data Science
Suppose you could flip this equation on its head and simplify or eliminate portions of the data preparation phase. Then, your data science team could spend more of its time on analysis and model building instead of accessing, moving, cleaning, and preparing data. Devron’s federated machine learning platform enables data science teams to do just that. Instead of the arduous task of bringing data to your model, you bring the model to your distributed data.

Automatic model training on distributed datasets without moving the data makes much of the ETL pipeline obsolete. By leaving the data where it resides, data science teams no longer need to waste time extracting, combining, loading, or refreshing data. Instead, they can simplify their to-do list, going from the cleaning phase straight into feature engineering and choosing an algorithm.
The data access process is also drastically streamlined as a result, given that data is left where it is on local systems—safe and secure. This significantly reduces the time it takes to gain approvals, as well as the level of involvement necessary for legal teams. No data lineage issues, no risk of privacy leakage in motion, no duplicate infrastructure for data storage. Additionally, training directly on the raw data without exposing the underlying source information allows data scientists to build better models and analyze sensitive data without compromising valuable signals.
As a result, using Devron's platform enables your data science team to spend up to 5x more time on value-add tasks, like model building and analysis. In addition, it blunts the primary driver of job dissatisfaction by significantly reducing the tasks they find least enjoyable, thus improving retention.
Therefore, Devron offers a unique solution to the data talent crisis by (1) increasing productivity, (2) minimizing administrative tasks, and (3) allowing them to focus more on analysis, resulting in higher job satisfaction. These benefits mean time savings across the workflow, reduced resources necessary for each data science project, and higher retention. Ultimately, Devron can enable organizations to do more data science with fewer data scientists.
To learn more about how Devron can increase the efficiency of your data science team by eliminating the costly tasks associated with centralizing data, request a demo today.


